
- Зачем и для чего делают зеркала сайтов?
- Поиск дублей страниц
- Ручной поиск
- Популярные варианты дублирования страниц
- Яндекс Вебмастер
- Google Search Console
- Поиск неполных дублей
- 1. Ищем при помощи вебмастера Google или сервиса Xenu
- 2. Ищем в строке поиска Яндекса или Google
- Как выявить дубли страниц?
- 1. Парсинг сайта в сервисе
- 2. Использование панели Яндекс.Вебмастер
- 3. Использование Google Search Console
- 4. Использование операторов поиска
- 5. Ручной поиск
- Чем опасны дубли для продвижения
- 1. Затрудняется индексация сайта (и определение основной страницы)
- 2. Основная страница в выдаче может замениться дублем
- 3. Потеря внешних ссылок на основную страницу
- 4. Риск попадания под фильтр ПС
- 5. Потеря значимых страниц в индексе
- Как удалить дубли страниц
- Метатег robots
- 301 редирект
- Атрибут rel=»canonical»
- Файл robots.txt
- Итог
- Основные виды переадресации и решаемые ими задачи
- Как избавиться от дубликатов страниц: основные виды и методы
- Как найти дубли сайта онлайн с помощью Saitreport
- Чем грозят дубли страниц для сайта?
- Как их найти и удалить?
- Виды и причины возникновения
- Как найти страницы-дубли
- Как удалить?
- Инструменты, необходимые для проведения полноценного аудита
- Панель вебмастера Яндекса
- Google Search Console (Панель для веб-мастеров)
- Выводы
Зачем и для чего делают зеркала сайтов?
Если вы еще не поняли, для чего конкретно создаются зеркала, расскажу на конкретных примерах.
Я могу сделать зеркало сайта на другом, более красивом домене, чтобы впоследствии перенести туда сайт, сохранив и поисковый трафик, и закладочную аудиторию постоянных посетителей (предварительно подготовив их к переезду на красивый домен). Такие случаи часто возникают в коммерции при слиянии и поглощении фирм — когда наименование и адрес новой объединенной компании должны измениться. Поэтому надо склеить новый домен с существующим.
Я могу «забронировать» домен. Сделаю зеркало сайта для бронирования схожих адресов. Например: kondicionery.ru и konditsionery.ru, fotostudiya.ru и fotostudia.ru. Еще пример: seo-moscow.ru и moscow-seo.ru. Зачем? Ну, для защиты от конкурентов, на всякий случай. Много причин. Иногда бывает так что, допустим, «fotostudia» пользователю проще запомнить и ввести — и речь не только об адресной строке браузера, но и о поисковых запросах. Статистика по запросам изобилует всевозможными опечатками и ошибками: «фольцваген», «ай фон» и др.
Из этого вытекает следующая цель.
Я могу сделать зеркало сайта для продвижения в нескольких странах на разных языках. Пример из жизни: computeruniverse.net, computeruniverse.de, computeruniverse.ru (русская версия что-то не работает в последнее время, вообще работала).
Про создание зеркал с целью стабильной доступности сайта я уже говорил — подобная схема не только обеспечит доступ к сайту в случае падения основного сервиса, но и распределит нагрузку по нескольким серверам т.е. в целом сайт будет всегда отзываться быстрее чем с одного «перегруженного» сервера.
Я могу сделать зеркало сайта, чтобы вывести его из под фильтра. Допустим, зафильтровал Яндекс сайт под одним доменом (или заблокировал Роскомнадзор по IP), а я делаю зеркало на новом сервере, делаю редирект — и снова в топе. Не страшны ни фильтры Яндекса, ни блокировки.
Сейчас расскажу, как создать зеркало для сайта с двумя распространенными целями: объединим домены с «www.» на обычный (+ обратно) и сделаем сайт-зеркало с новым доменом.
Поиск дублей страниц
Ручной поиск
- Первое, что можно сделать для быстрого обнаружения – сделать поиск по запросу «site:ваш сайт» в Яндекс/Google и посмотреть количество найденных страниц. Такой запрос выводит все страницы с вашего сайта, попавшие в индекс поисковика.
- Конкретно для систем Google можно воспользоваться расширенным поиском. Необходимо ввести сайт с конкретной страницей – гугл выдаст дубли страниц. Так проходим по каждой странице на сайте.
- Еще один надежный способ обнаружения – ручной ввод возможных адресов сайта.
Популярные варианты дублирования страниц
Заходим на какую-нибудь страницу своего сайта и начинаем экспериментировать:
http://site.ru/category/post1- исходный адрес, на который мы перешли в процессе навигации по сайту. Все остальные варианты должны либо исправиться автоматически на этот адрес, либо выдать, что страница не существует.
http://www.site.ru/category/post1
http://site.ru/category/post1.html
http://site.ru/category/post1.php
http://site.ru/category/post1/index.php
http://site.ru/category/post1/index.html
http://site.ru/post1/ — часто страница доступна в нескольких категориях и без категории
http://site.ru/category/post1?param=234234
http://site.ru/category/post1/index.php
http://site.ru/category/post1— (добавляем и убираем косую черту в конце, это тоже считается разный адрес)
Обычно, если проблема есть, то этих проверок достаточно.
Яндекс Вебмастер
Простой способ найти дубли через Яндекс Вебмастер
- Переходим в Вебмастер и нажимаем СТРАНИЦЫ В ПОИСКЕ
- Выбираем ПОСЛЕДНИЕ ИЗМЕНЕНИЯ
- Выгружаем архив – смотрим на статус страниц. Если обнаружен дубль, тогда вы увидите DUPLICATE.
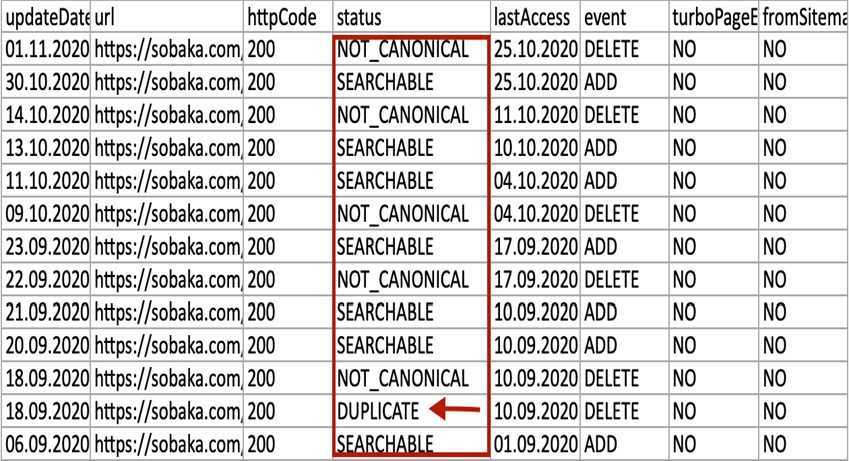 Поиск дублей через Яндекс Вебмастер
Поиск дублей через Яндекс Вебмастер
Можно не выгружать, а воспользоваться фильтром прямо в Яндекс.Вебмастер и просматривать существующие дубли прямо в браузере онлайн.
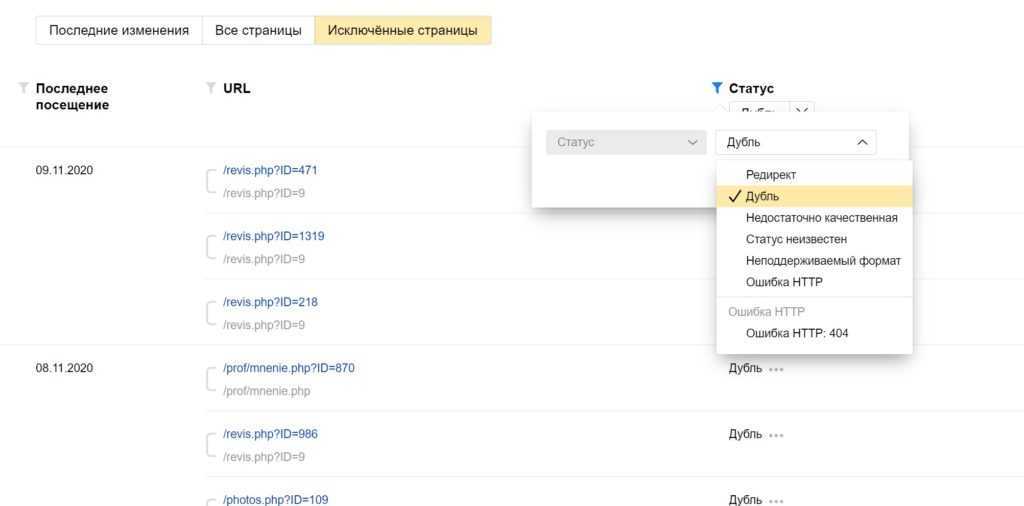 Выбираем фильтр по статусу «Дубль»
Выбираем фильтр по статусу «Дубль»
Google Search Console
Через Google Search Console дубликаты можно увидеть еще быстрее.
- Заходим на вкладку ПОКРЫТИЕ
- Выбираем ИСКЛЮЧЕННЫЕ и смотрим на сведения
- В списке будут указаны страницы, которые являются копией.
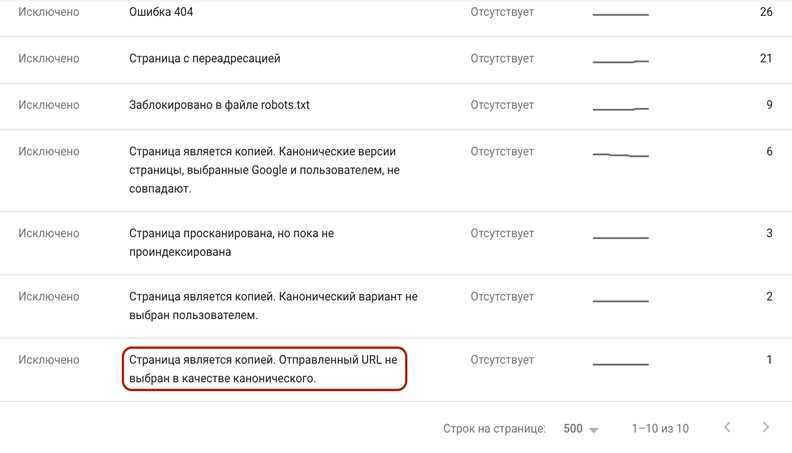 Поиск дублей через Google Console
Поиск дублей через Google Console
Поиск неполных дублей
1. Ищем при помощи вебмастера Google или сервиса Xenu
Алгоритм действий в этих сервисах абсолютно такой же, как и для поиска полных дублей. Единственное отличие заключается в том, что среди найденных дублей необходимо отобрать те страницы, которые имеют идентичные Title и/или Description, но совершенно разный контент.
В результате поиска в Google мы обнаружили группу неполных дублей (Рис. 2).
Рис. 2. Совершенно разные новости с дублированными мета-данными
2. Ищем в строке поиска Яндекса или Google
Страницы с частично похожим контентом, но разными мета-данными указанным выше способом выявить не удастся. В этом случае придется работать вручную.
Для начала условно выделите зоны риска:
- скудный контент (сквозные блоки по объему превосходят основной текст страницы);
- копированный контент (описание схожих товаров);
- пересечение контента (анонсы, рубрики/подкаталоги, фильтры, сортировка).
Из каждой группы выберите несколько страниц.
Для наглядной иллюстрации примера мы воспользовались одной из карточек товаров на сайте мебельного магазина, проходившего аудит в нашей рубрике «Экспертиза». Вероятность появления дублей здесь достаточно высока, так как в карточках преобладают картинки и сквозные блоки, а уникальный контент сведен к минимуму.
Указываем в строке поиска Google фрагмент текста из описания товара, заключенный в кавычки, и домен сайта с оператором site: (Рис. 3).
Рис. 3. Поиск дублей на сайте по фрагменту текста и домену
На представленном скриншоте хорошо видно, что карточка товара отсутствует в индексе Google. Проверка в Яндексе данной страницы, а также товаров из других категорий этого сайта дала аналогичный результат. Соответственно, данные страницы потеряны для привлечения трафика из поиска.
Также для примера проверим отрезок текста одной из новостей магазина (Рис. 4).
Рис. 4. Поиск дублей на сайте по фрагменту новости
Аналогично поступим и с парой других новостей. По запросу поиск выдает ссылку на список всех новостей, но ни одна уникальная новость не попала в индекс. Часто бывает обратная ситуация: в индекс попадает несколько дублей (сама новость, анонс новости в списке новостей, анонс новости на разных страницах пагинации (если пагинация настроена некорректно)). В таком случае в выдаче появляется сразу несколько ссылок на один и тот же контент.
Проверьте аналогичным способом (при помощи отрезка текста и оператора site:) фрагменты контента товарных страниц, страниц услуг, новостей, анонсов и других значимых для продвижения разделов. При обнаружении проблем переходите к следующему шагу.
Как выявить дубли страниц?
Способов обнаружить дубликаты страниц — множество. В данной статье рассмотрим несколько основных методов, которые используются в работе чаще всего.
1. Парсинг сайта в сервисе
При парсинге сайта в каком-либо сервисе (в последнее время чаще всего используют сервис Screaming Frog) наглядно можно увидеть страницы-дубликаты.
К примеру, когда не склеены зеркала либо у страниц есть какие-то параметры, которые добавляются автоматически при отслеживании эффективности рекламных кампаний и др.

Рис. 2. Пример парсинга сайта в сервисе Screaming Frog при не склеенных зеркалах
Небольшой лайфхак для работы с сервисом Screaming Frog: если у сайта огромное количеством страниц, и вы сразу заметили, что зеркала не склеены и поставили проект на парсинг, естественно процесс замедлится и уменьшит скорость работы вашей системы (если у вашего ПК, конечно, не мощные системные характеристики).
Чтобы этого избежать можно использовать функцию Configuration – URL Rewriting – Regex Replace.
В вкладке Regex Replace создаем следующее правило (используя регулярное выражение, «говорим» сервису, как нужно склеивать зеркала, чтобы он выводил только страницы с HTTPS):
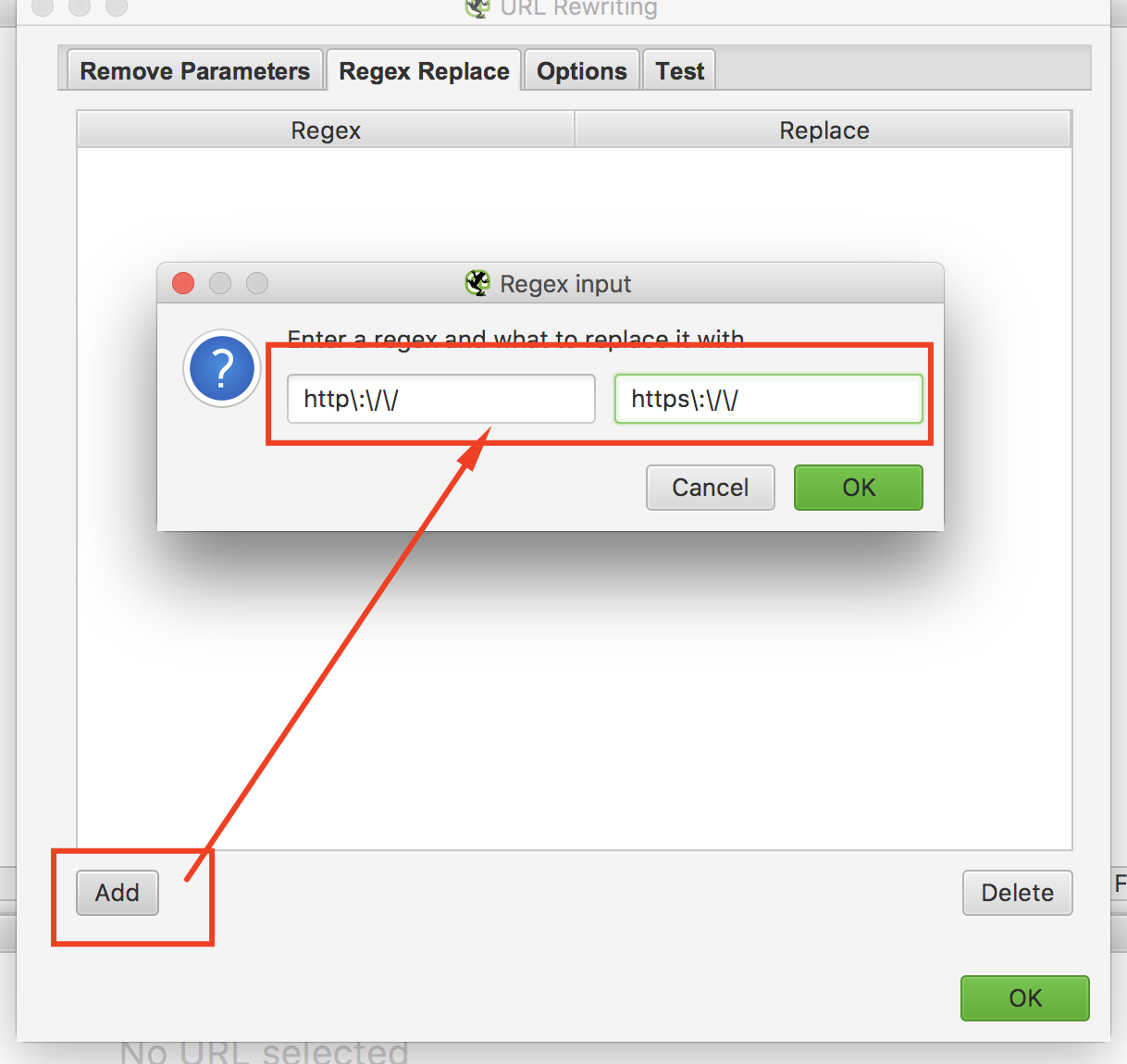
Рис. 3. Скриншот из сервиса Screaming Frog — Использование функции URL Rewriting
Далее нажимаем кнопку «ОК» и переходим во вкладку «Test». В данной вкладке сервис вам покажет, правильно ли вы задали правило и как будут склеиваться зеркала. В нашем случаем должен выходить такой результат:
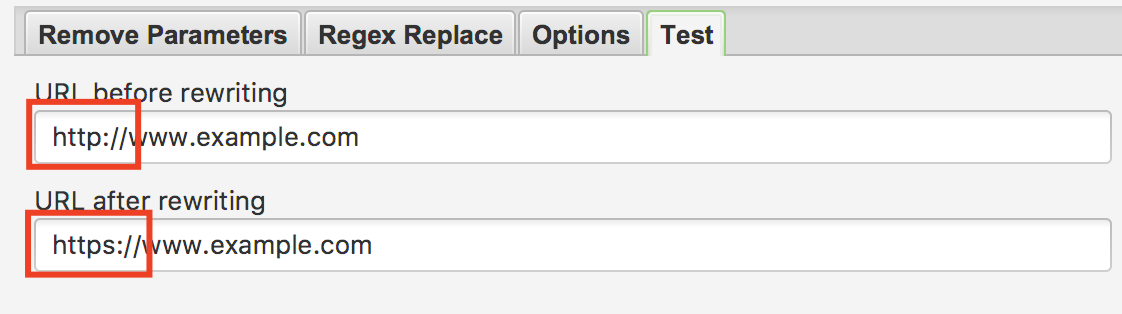
Рис. 4. Скриншот из сервиса Screaming Frog — Использование функции Test
Таким же способом можно склеивать страницы с «www» и без «www», а также задавать различные параметры, чтобы не выводить ненужные страницы (например, страницы пагинации).
После всех операций спокойно запускаем парсинг сайта без дополнительной нагрузки на систему.
2. Использование панели Яндекс.Вебмастер
В Яндекс.Вебмастер есть очень удобный пункт сервиса — «Индексирование» — «Страницы в поиске». Данный пункт наглядно показывает текущую индексацию сайта, а также дубликаты страниц (то, что мы ищем):
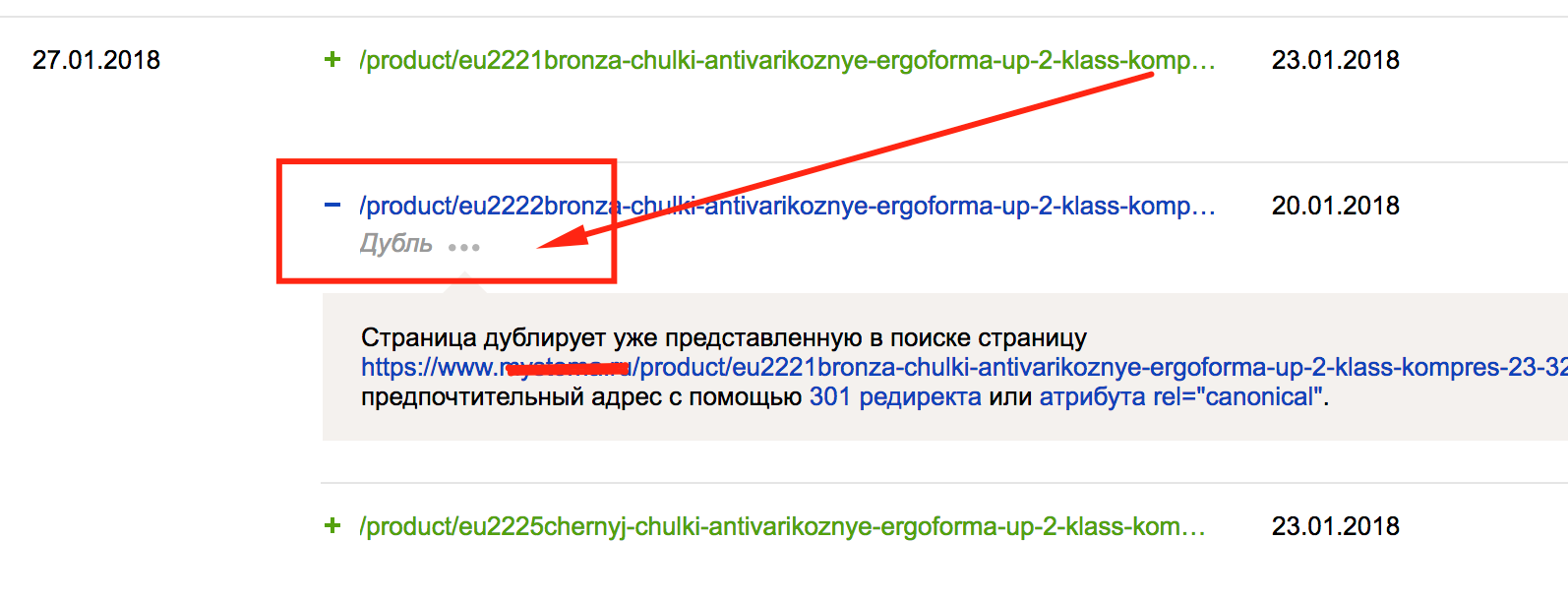
Рис. 5. Скриншот из панели Яндекс.Вебмастер — Использование функции Страницы в Поиске
Для полного анализа дубликатов страниц рекомендуется выгрузить xls-файл всех страниц, которые присутствуют в поиске:

Рис. 6. Выгрузка страниц в поиске из панели Яндекс.Вебмастер
Открываем наш xls-файл и включаем фильтр: Данные – Фильтр:
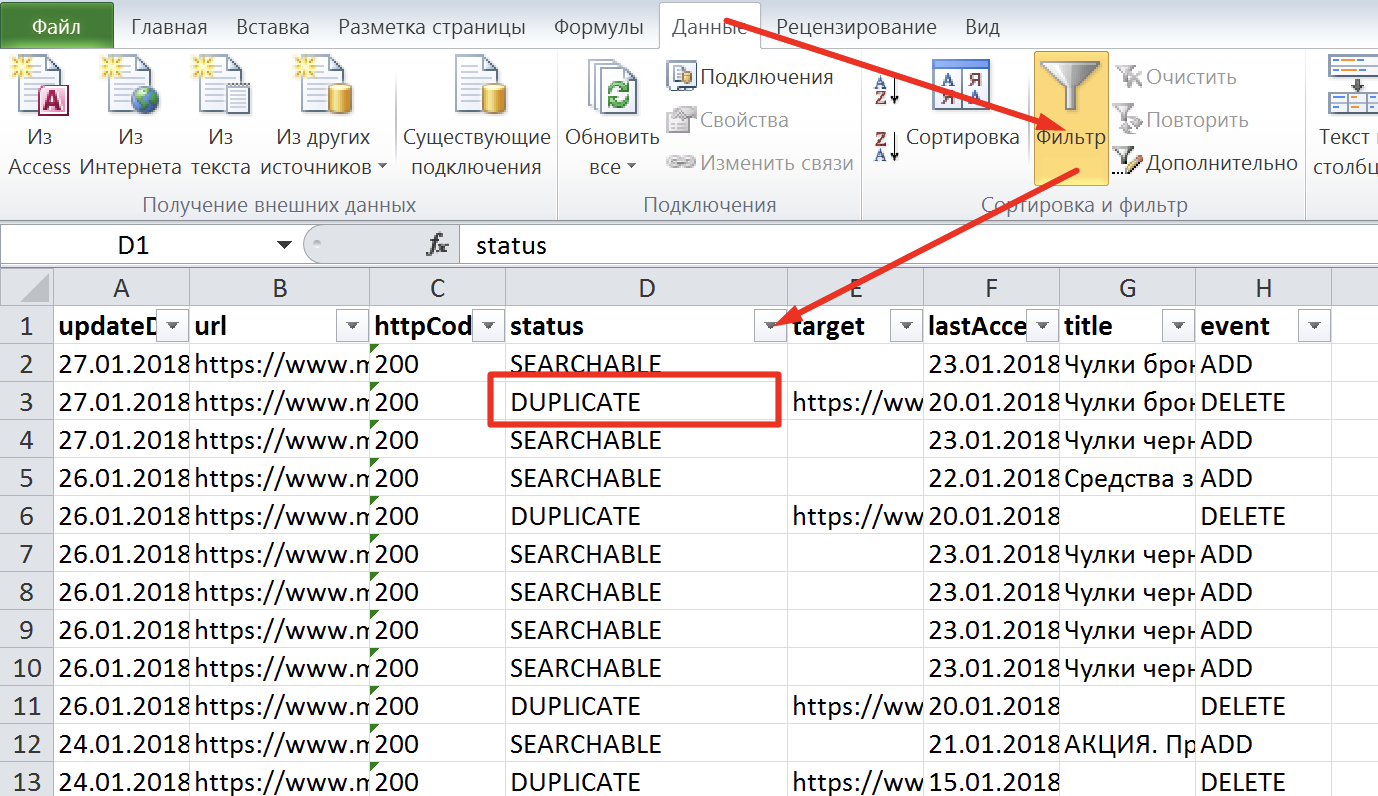
Рис. 7. Скриншот из xls-файла «Выгрузка страниц в поиске из панели Яндекс.Вебмастер»
В фильтре выбираем «DUPLICATE», и перед нами будет список дубликатов страниц. Рекомендуется проанализировать каждую страницу или один тип страниц, (если, например, это только карточки товаров) на предмет дублирования.
Например: поисковая система может признать дубликатами похожие карточки товаров с незначительными отличиями. Тогда необходимо переписать содержание страницы: основной контент, теги и метатеги, если они дублируются, либо такие карточки склеить с помощью атрибута rel=”canonical”. Другие рекомендации по избавлению от дубликатов страниц подробно описаны в пункте 5.
3. Использование Google Search Console
Заходим в Google Search Console, выбираем свой сайт, в левом меню кликаем «Вид в поиске» – «Оптимизация HTML» и смотрим такие пункты, которые связаны с термином «Повторяющееся»:
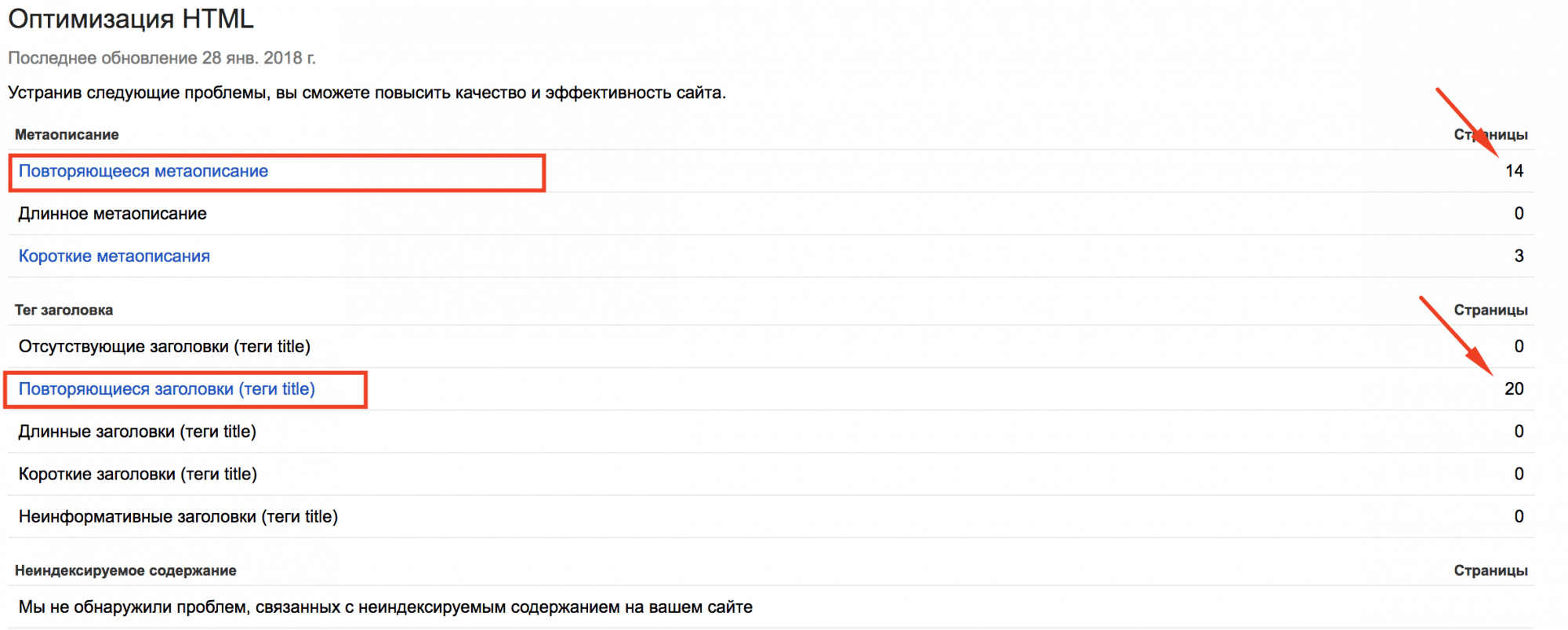
Рис. 8. Скриншот из панели «Google Console»
Данные страницы могут и не являются дубликатами, но проанализировать их нужно и при необходимости устранить проблемы с дублированием.
4. Использование операторов поиска
Для поиска дубликатов также можно использовать операторы поиска «site:» и «inurl», но данный метод уже устарел. Его полностью заменила функция «Страницы в поиске» в Яндекс.Вебмастере.
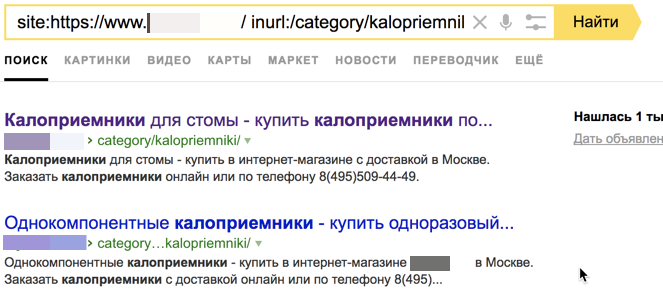
Рис. 9. Скриншот из поисковой выдачи – использование поисковых операторов
5. Ручной поиск
Для ручного поиска дубликатов страниц необходимо уже обладать знаниями о том, какие дубликаты могут быть. Вручную обычно проверяются такие типы дубликатов, как:
一 добавление в URL-адрес каких-либо символов в конце адреса или в середине. Если после перезагрузки страница не отдает 404 код ответа сервера или не настроен 301 Moved Permanently на текущую основную страницу, то перед нами, по сути, тоже дубликат, от которого необходимо избавиться. Такая ошибка является системной, и ее нужно решать на автоматическом уровне.
Чем опасны дубли для продвижения
1. Затрудняется индексация сайта (и определение основной страницы)
Из-за дублей количество страниц в базе поисковых систем может увеличиться в несколько раз, некоторые страницы могут быть не проиндексированы, т. к. на обход сайта поисковому роботу выделяется фиксированная квота количества страниц.
Усложняется определение основной страницы, которая попадет в поисковую выдачу: выбор робота может не совпасть с выбором вебмастера.
2. Основная страница в выдаче может замениться дублем
Если дубль будет получать хороший трафик и поведенческие метрики, то при очередном апдейте он может заменять основную (продвигаемую) страницу в выдаче. При этом позиции в поиске «просядут», т.к. дубль не будет иметь ссылочной популярности.
3. Потеря внешних ссылок на основную страницу
Желающие поделиться ссылкой на сайт могут ошибочно ссылаться на страницы-дубли. Ссылочный вес будет «размазан» между страницами, и ситуация с определением наиболее релевантной версии усугубится.
4. Риск попадания под фильтр ПС
И Яндекс, и Google борются с неуникальным контентом, в связи с чем могут применить к «засоренному» сайту фильтры АГС и Panda.
5. Потеря значимых страниц в индексе
Неполные дубли (страницы категорий, новости, карточки товаров и т. д.) из-за малой уникальности имеют шанс не попасть в индекс поисковиков вообще. Например, это может случиться с частью товарных карточек, которые поисковый алгоритм сочтет дублями.
Как удалить дубли страниц
После обнаружения дублей, первое, что необходимо сделать — найти причину, из-за которой они появляются, и постараться ее устранить.
Выделяют четыре основных метода удаления дублей:
- <meta name=»robots» content=»noindex»>;
- 301 редирект;
- rel=»canonical»;
- robots.txt.
Метатег robots
Позволяет задать роботам правила загрузки и индексирования определенных страниц сайта. Учитывается поисковой системой «Яндекс» и Google.
Метатег <meta name=»robots» content=»noindex» /> следует разместить в HTML-коде дублирующихся страниц в разделе <head>.
Пример:
<!DOCTYPE html><html><head><meta name=»robots» content=»noindex» />(…)</head><body>(…)</body></html>
Заданное для атрибута content значение noindex запрещает поисковым системам показывать страницу в результатах поиска.
Больше информации о специфике и применении метатега robots вы найдете в справочных материалах и «Яндекс».
301 редирект
Несомненно, один из самых действенных и известных методов устранения дублей, который позволяет автоматически перенаправить пользователей с одной страницы на другую. 301 редирект говорит поисковым системам о том, что старый URL-адрес имеет новый путь на постоянной основе. Со временем два или больше документа «склеиваются» в один, на который ведет перенаправление. При этом ссылочный вес сохраняется, поскольку передается со старой страницы на новую.
Настройка осуществляется через редактирование файла .htaccess либо с помощью плагинов.
Вот несколько плагинов для CMS WordPress:
- Redirection
- Simple 301 Redirects
- Safe Redirect Manager
Владельцам сайтов на движке Joomla достаточно воспользоваться встроенным менеджером перенаправлений.
Прежде чем настроить редирект в файле .htaccess, сначала сделайте его бэкап (резервное копирование).
Например, чтобы задать редирект с www на без www, разместите одно из правил:
RewriteEngine OnRewriteCond %{HTTP_HOST} ^www\.(.*)$RewriteRule ^(.*)$ http://%1/$1
или
RewriteEngine OnRewriteCond %{HTTP_HOST} ^www\.(.*)$ RewriteRule ^(.*)$ http://%1/$1
Переадресация с одной статической страницы на другую осуществляется за счет добавления строки:
Redirect 301 /old-page http://yoursite.com/new-page
где:
- old-page — страница, с которой происходит редирект;
- new-page — страница, на которую установлен редирект.
Атрибут rel=»canonical»
Укажите каноническую страницу, чтобы показать поисковым системам, какую страницу нужно индексировать при пагинации, сортировке, попадании в URL GET-параметров и UTM-меток. Этот способ уместен, когда удалять страницу нельзя и её нужно оставить открытой для просмотра. Учитывается поисковой системой «Яндекс» и Google.
Указывая каноническую ссылку, мы указываем адрес страницы, предпочтительной для индексации. Атрибут rel=»canonical» нужно прописать между тегами <head>…</head> на всех страницах, которые являются дублями.
Например, страница доступна по двум адресам: yoursite.com/pages?id=2 и yoursite.com/blog.
Если предпочитаемый URL — /blog, добавьте в HTML-код страницы /pages?id=2 элемент link:
<link rel=»canonical» href=»http://www.example.com/blog»/>
Больше информации о специфике применения атрибута rel=»canonical» вы найдете в справочных материалах и «Яндекс».
Файл robots.txt
Еще одно решение — запретить роботам индексировать дубликаты, дописав в файл robots.txt директиву Disallow. Чаще всего используется в тех случаях, когда нужно запретить индексацию служебных страниц и дублей.
Например, закрыть страницы пагинации от индексации Joomla поможет:
Disallow: /?start*
Учтите, директивы в robots.txt носят рекомендательный характер и могут быть проигнорированы поисковыми роботами, но как правило, они учитывают данное указание.
Итог
Дубли страниц — проблема из разряда «крупногабаритных и тяжеловесных». Если вовремя не отреагировать, все дальнейшие усилия по продвижения могут быть сведены на нет. Надеемся, представленные в этой статье методы помогут оптимизировать ваш ресурс и занять топовые места в поисковой выдачи.
Основные виды переадресации и решаемые ими задачи
Переадресация (перенаправление, редирект) представляет собой способ отправки пользователей и поисковых роботов с запрашиваемого URL-адреса на другой. Рассмотрим несколько наиболее часто используемых редиректов:
301-й («перемещено навсегда»). В большинстве случаев, 301-й редирект является лучшим методом для реализации перенаправления на веб-сайте. Он указывает, что страница была перемещена на постоянной основе. При этом данный редирект очень удачно сочетается с поисковой оптимизацией, поскольку позволяет передать вес ссылок со старой страницы на новую.
302-й («перемещено временно»). Не передает веса ссылок на перемещенную страницу. Чаще всего используется, когда необходимо протестировать новую страницу, но при этом охранить все свойства и уровень ранжирования старого документа (страницы).
Полный перечень перенаправлений см. на странице — http://ru.wikipedia.org/wiki/Список_кодов_состояния_HTTP
Как избавиться от дубликатов страниц: основные виды и методы
В данном пункте разберем наиболее часто встречающиеся виды дубликатов страниц и варианты их устранения:
- Не склеенные страницы с «/» и без «/», с www и без www, страницы с http и с https.
Варианты устранения:
一 Настроить 301 Moved Permanently на основное зеркало, обязательно выполните необходимые настройки по выбору основного зеркала сайта в Яндекс.Вебмастер.
- Страницы пагинации, когда дублируется текст с первой страницы на все остальные, при этом товар разный.
Выполнить следующие действия:
一 Использовать теги next/prev для связки страниц пагинации между собой;
一 Если первая страница пагинации дублируется с основной, необходимо на первую страницу пагинации поставить тег rel=”canonical” со ссылкой на основную;
一 Добавить на все страницы пагинации тег:
Данный тег не позволяет роботу поисковой системы индексировать контент, но дает переходить по ссылкам на странице.
- Страницы, которые появляются из-за некорректно работающего фильтра.
Варианты устранения:
一 Корректно настроить страницы фильтрации, чтобы они были статическими. Также их необходимо правильно оптимизировать. Если все корректно настроено, сайт будет дополнительно собирать трафик на страницы фильтрации;
一 Закрыть страницы-дубликаты в файле robots.txt с помощью директивы Disallow.
- Идентичные товары, которые не имеют существенных различий (например: цвет, размер и т.д.).
Варианты устранения:
一 Склеить похожие товары с помощью тега rel=”canonical”;
一 Реализовать новый функционал на странице карточки товара по выбору характеристики. Например, если есть несколько почти одинаковых товаров, которые различаются только, к примеру, цветом изделия, то рекомендуется реализовать выбор цвета на одной карточке товара, далее – с остальных настроить 301 редирект на основную карточку.
- Страницы для печати.
Вариант устранения:
一 Закрыть в файле robots.txt.
- Страницы с неправильной настройкой 404 кода ответа сервера.
Вариант устранения:
一 Настроить корректный 404 код ответа сервера.
- Дубли, которые появились после некорректной смены структуры сайта.
Вариант устранения:
一 Настроить 301 редирект со страниц старой структуры на аналогичные страницы в новой структуре.
- Дубли, которые появляются из-за некорректной работы Яндекс.Вебмастера. Например, такие URL-адреса, которые заканчиваются на index.php, index.html и др.
Варианты устранения:
一 Закрыть в файле robots.txt;
一 Настроить 301 редирект со страниц дубликатов на основные.
- Страницы, к примеру, одного и того же товара, которые дублируются в разных категориях по отдельным URL-адресам.
Варианты устранения:
一 Cклеить страницы с помощью тега rel=”canonical”;
一 Лучшим решением будет вынести все страницы товаров под отдельный параметр в URL-адресе, например “/product/”, без привязки к разделам, тогда все товары можно раскидывать по разделам, и не будут “плодиться” дубликаты карточек товаров.
- Дубли, которые возникают при добавлении get-параметров, различных utm-меток, пометок счетчиков для отслеживания эффективности рекламных кампаний: Google Analytics, Яндекс.Метрика, реферальных ссылок, например, страницы с такими параметрами как: gclid=, yclid=, openstat= и др.
Варианты устранения:
一 В данном случае необходимо проставить на всех страницах тег rel=”canonical” со ссылкой страницы на саму себя, так как закрытие таких страниц в файле robots.txt может повредить корректному отслеживанию эффективности рекламных кампаний.
Устранение дублей позволит поисковым системам лучше понимать и ранжировать ваш сайт. Используйте советы из этой статьи, и тогда поиск и устранение дублей не будет казаться сложным процессом.
И повторюсь: малое количество дубликатов не так значительно скажется на ранжировании вашего сайта, но большое количество (более 50% от общего числа страниц сайта) явно нанесет вред.
Как найти дубли сайта онлайн с помощью Saitreport
Еще один способ, как найти дубли сайта — через сервис Saitreport. Я записывал обзор по этому сервису, посмотрите видео:
https://youtube.com/watch?v=XWXAxh_c1lg
Вкратце скажу, что дубли страниц можно найти во вкладке «Контент», спускаемся вниз и здесь вот есть «Полные дубликаты», «Почти дубликаты» и «Очень похожие».
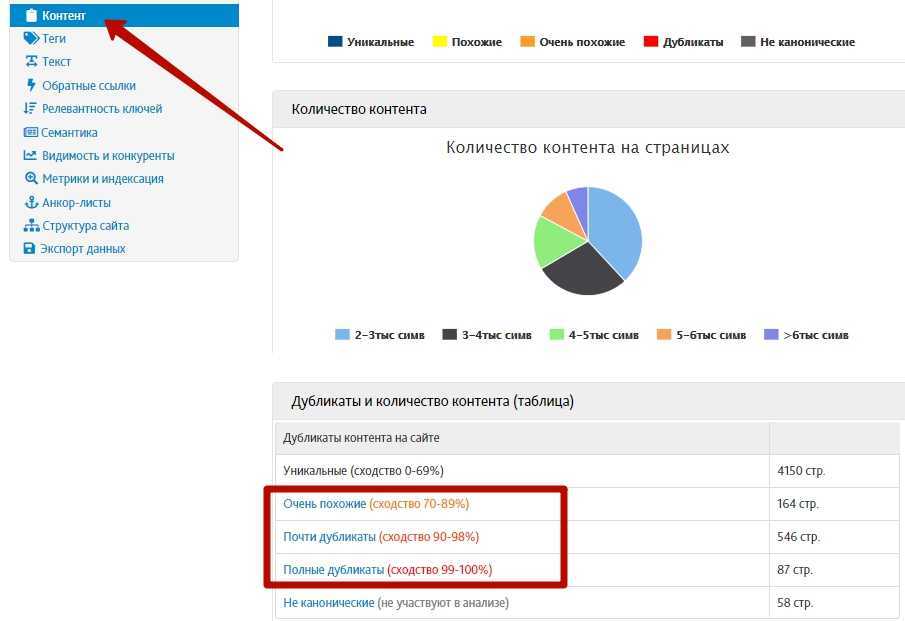
Нас интересуют вот эти полные совпадения и почти дубликаты, особенно полные совпадения, переходим сюда и видим, что достаточно много дублей.
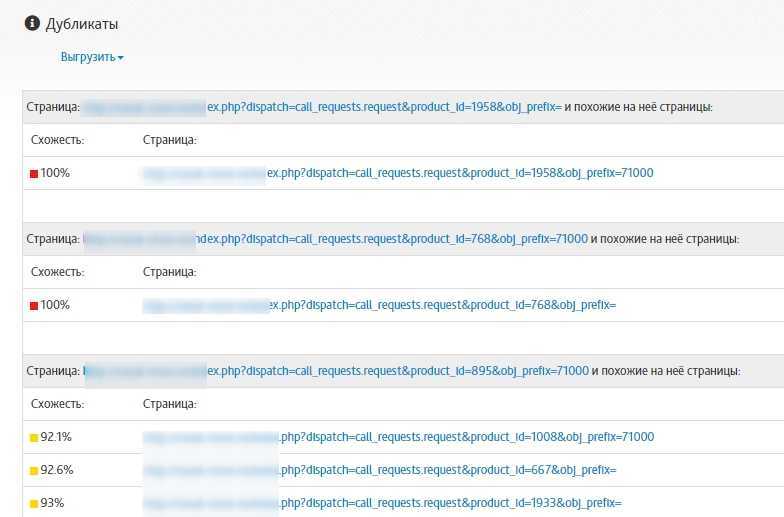
По URL видно, что эта страницы фильтров, две полностью идентичные страницы. Самое главное, чтобы фильтр был закрыт от индексации, чтобы весь этот мусор не попал в индекс. Если это просто находится на сайте, но не в индексе, то ничего страшного нет, но если этот мусор попадет в индекс, то можно легко похерить сайт.
Чем грозят дубли страниц для сайта?
Как их найти и удалить?
Всем известно, что успех сайта во многом зависит от того, как его воспринимают поисковые системы. Поисковые системы очень негативно относятся к неуникальным материалам сайтов. При ранжировании страниц роботу сложно определить страницу-первоисточник. Вряд ли неуникальный сайт окажется в первых строках поисковой страницы.
Но бывает так, что весь материал на сайте написан лично автором на основании собственного опыта, а при вводе части текста в строку поиска в результате выдается две, а то и три страницы с точно таким же текстом. Это страницы-дубли одного и того же сайта.

Виды и причины возникновения
Страницы-дубли можно разделить на две группы: полные и неполные.
Полные дубли – это страницы с полностью одинаковым содержимым. Неполные дубли содержат существенную часть текстов с других страниц, но не весь текст. И те, и другие не лучшим образом скажутся на ранжировании страниц сайта.
Чаще всего, полные страницы-дублеры появляются из-за разных недоработок и ошибок шаблонов CMS. А также установка различных модулей и компонентов может спровоцировать появление страниц с одинаковыми содержимым и адресами, но с разными расширениями (www.***.php, www.***.html и т.д.)
Смена дизайна, изменение структуры сайта также может способствовать появлению дублеров. Связано это с тем, что в процессе смены могут появиться страницы с новым адресом, а на старых адресах останутся те же страницы с тем же содержимым.
Ну и последняя причина полных дублей – человеческий фактор. Вебмастер сам может нечаянно создать дубли страниц, ошибившись в написании кода.
Неполные страницы-дублеры появляются по двум причинам. Во-первых, если содержание станиц слишком мало и их сквозные части, такие как шапка, подвал и боковые колонки, составляют основную часть страницы. Во-вторых, если какие-то части материала без изменения помещаются на разных страницах.
Как найти страницы-дубли
Самый простой метод поиска – это поисковая система. Следует ввести в строку поиска 1-2 предложения из текста со страницы, которую нужно проверить. Отметить, что поиск следует вести только на исследуемом сайте. В результате поиска появятся все страницы сайта, содержащие искомый текст. Также поисковая система выдаст все страницы с неполными дублями.
Можно искать дублеры при помощи специальных программ, таких как Xenu’s Link Sleuth. Они, исследуя сайт, выявляют все его страницы. Затем можно найти дубли либо по повторяющимся адресам, либо по заголовку страницы.
Анализ проиндексированных поисковыми системами страниц производится при помощи специальных поисковых запросов. В разных системах эти запросы разные.
Как удалить?
Если таких страниц немного, удалить их можно вручную.
Если выясняется, что на сайте много однотипных дублей, например, страницы с адресами, содержащими идентификатор сессий, то такие страницы можно запретить для индексации. Делается это при помощи команды «Disallow», которая прописывается в файле robots.txt.
Избавиться от множества одинаковых страниц возможно также при помощи автоматической переадресации на одну страницу-первоисточник. Делается это настройкой редиректа 301 в файле htaccess.
Ну и, пожалуй, последний способ — код HTML, прописанный на страницах. Он дает понять поисковым роботам, какую страницу считать первоисточником. В самых популярных системах CMS эти коды генерируются автоматически.
(Visited 109 times, 1 visits today)
Инструменты, необходимые для проведения полноценного аудита
Панель вебмастера Яндекса
Как только вы создаете сайт, либо берете клиентский сайт на продвижение, первое, что надо сделать – получить (создать) доступ в панель Яндекс.Вебмастер и Яндекс.Метрику. Это не требует никаких специальных знаний. Потом зайдите в раздел уведомлений в панели Вебмастера.
Нет времени объяснять, просто смотрите:

Важно ли это? Очень важно!
Панель вебмастера Яндекса обрела новую жизнь, когда ее обновили до версии 2.0. В разделе диагностики сообщают о критических и возможных проблемах и выдают рекомендации. В разделе безопасность сообщают о вирусах и вредоносном коде, в нарушениях – о наложенных фильтрах (например, если вы перестарались со ссылками и получили Минусинск).
Следующий важный раздел – Индексирование – где можно посмотреть, какие страницы проиндексированы, какие участвуют в поиске, а какие отдают ошибки.
Отдельное спасибо за то, что все данные из панели можно выгружать в виде архива, где, по их словам, содержится исчерпывающая информация. Жалко, что с этими данными нельзя взаимодействовать, например, отметить проблемы с несуществующими или запрещенными к индексации страницами, как решенные, чтобы пропали из статистики, как это сделано в Google Search Console. Но с другой стороны, забот меньше, не так ли? 
Что еще стоит обязательно сделать в панели вебмастера Яндекса:
- Добавить файлы sitemap.xml;
- В разделе Переезд сайта указать основное зеркало;
- В разделе «Региональность» указать регион, либо убедиться, что указан нужный регион;
- Выбрать регистр сайта. Просто для красоты, либо в надежде, что это немного увеличит CTR на выдаче;
- В Быстрых ссылках провести ревизию, чтобы показывались только самые важные ссылки в нужном порядке. Об изменениях в быстрых ссылках приходят сообщения в «Уведомления»;
- Все остальное уже по ситуации и в зависимости от требований.
Обычно я договариваюсь с заказчиком, что все настройки в панели произвожу сам, потому что описывать, что и как сделать, намного дольше, чем все настроить самостоятельно.
Google Search Console (Панель для веб-мастеров)
Добавить сайт в панель Гугла – это такое же необходимое действие. Здесь есть раздел с важными сообщениями, где хранятся рекомендации для сайтов и сообщения об ошибках:
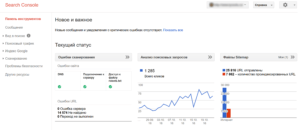
Сайт плохо индексируется? 404 ошибки? Вам сообщат!
Немного раздражает, что для указания главного зеркала сайта (Шестеренка в правом верхнем углу – Настройки сайта – Основной домен), необходимо все зеркала добавить и подтвердить в панели и только потом для зеркал указывать основной сайт. Потом все эти зеркала для всех сайтов будут в общем списке болтаться. Бесит!
Следующий важный раздел: Вид в поиске — Оптимизация HTML
Стоит обратить особое внимание на пункт «Повторяющиеся заголовки (теги title)». Дубликаты title говорят о серьёзны недочетах
Основных причин несколько: у вас некорректно формируются title, у вас есть дубликаты страниц, не закрыты от индексации «лишние» страницы.
Раздел «Меры, принятые вручную» – здесь по аналогии с Яндексом (на самом деле, это у Яндекса по аналогии с Гуглом) показываются примененные к сайту фильтры. Не все, а как следует из названия, а только наложенные вручную: фильтр за переоптимизацию и фильтр за ссылочный спам.
Сканирование – Ошибки сканирования – здесь вы найдете ошибки внутри сайта, связанные с недоступностью страниц, которые либо удалены, либо сервер вовремя не ответили или выдал ошибку. Таблицу можно выгрузить в архив, но исчерпывающих данных вы все равно не получите. Не знаю почему, но Гугл зажал полный список и отдает только часть. Зато решенные проблемы можно отметить, и они тут же пропадут из статистики.
Вообще в панели Гугла больше вопросов, чем ответов: зачем нам просто циферки, когда гораздо важнее знать, что за ними скрывается? В карте сайта проиндексировано 1000 страниц из 10000, и что дальше? Какие это страницы, почему не индексируются? Не понятно. Гугл очень скуп на информацию для веб-мастеров. Единственное, что можно выгрузить полностью – это беклинки.
Раньше я часто заходил в Серч Консоль, но с появлением Вебмастера 2.0 Яндекса я делаю это все реже и реже.
Выводы
Дублирование страниц — серьезная проблема, особенно если сайт находится на SEO-продвижении. Это не надуманная проблема и в кабинетах вебмастеров Яндекс и Гугл есть предупреждения о дублировании контента.
Дубли можно легко найти с помощью программ. Если это технические страницы, то их желательно удалить. Если страницы важны для пользователя, то можно просто закрыть от индексации.
Самые простой способ перестраховаться от дублирования страниц — это использование метатега Canonical для указания основного адреса.
← Как узнать какой используется блок на ТильдеВозможности поиска Google для профессионалов →
е